A collection of benchmark data sets for knowledge graph-based similarity in the biomedical domain
- Conference/Journal: Database
- Year: 2020
- Full paper URL: https://academic.oup.com/database/article/doi/10.1093/database/baaa078/5979744?login=true
Abstract
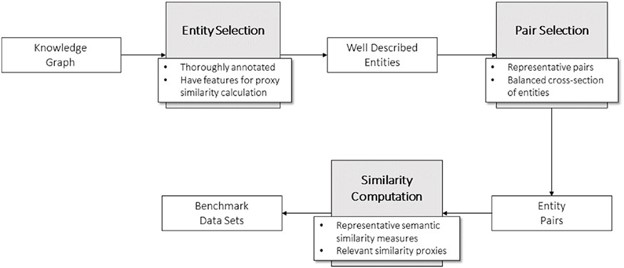
The ability to compare entities within a knowledge graph is a cornerstone technique for several applications, ranging from the integration of heterogeneous data to machine learning. It is of particular importance in the biomedical domain, where semantic similarity can be applied to the prediction of protein–protein interactions, associations between diseases and genes, cellular localization of proteins, among others. In recent years, several knowledge graph-based semantic similarity measures have been developed, but building a gold standard data set to support their evaluation is non-trivial.
We present a collection of 21 benchmark data sets that aim at circumventing the difficulties in building benchmarks for large biomedical knowledge graphs by exploiting proxies for biomedical entity similarity. These data sets include data from two successful biomedical ontologies, Gene Ontology and Human Phenotype Ontology, and explore proxy similarities calculated based on protein sequence similarity, protein family similarity, protein–protein interactions and phenotype-based gene similarity. Data sets have varying sizes and cover four different species at different levels of annotation completion. For each data set, we also provide semantic similarity computations with state-of-the-art representative measures.